안녕하세요. 애나입니다.
오늘은 Meta에서 새롭게 발표한 새로운 오디오 생성 모델 'Audiobox'를 소개해드려고 합니다. Meta에서 올해 초 제작했던 'Voicebox' 에서 더욱 발전한 모델로 음성이나 소리 효과를 텍스트 입력으로 쉽게 생성할 수 있는 오디오 생성 모델 입니다. 이 모델의 가장 큰 특징은 사용자가 원하는 소리나 음성 유형을 자연어로 서술하면, 그에 맞는 오디오를 생성한다는 점이죠. 예를 들어, "강물이 흐르는 소리와 새가 지저귀는 소리" 를 입력하면 원하는 사운드 스케이프를 쉽게 생성할 수 있습니다.

간단 요약
- AudioBox는 메타가 새롭게 발표한 오디오 생성을 위한 AI 모델 입니다.
- AudioBox 는 자연어 텍스트 프롬프트를 조합해서 음성 및 음향 효과를 생성할 수 있습니다.
- 원하는 상황에 맞는 맞춤형 오디오를 쉽게 생성할 수 있습니다.
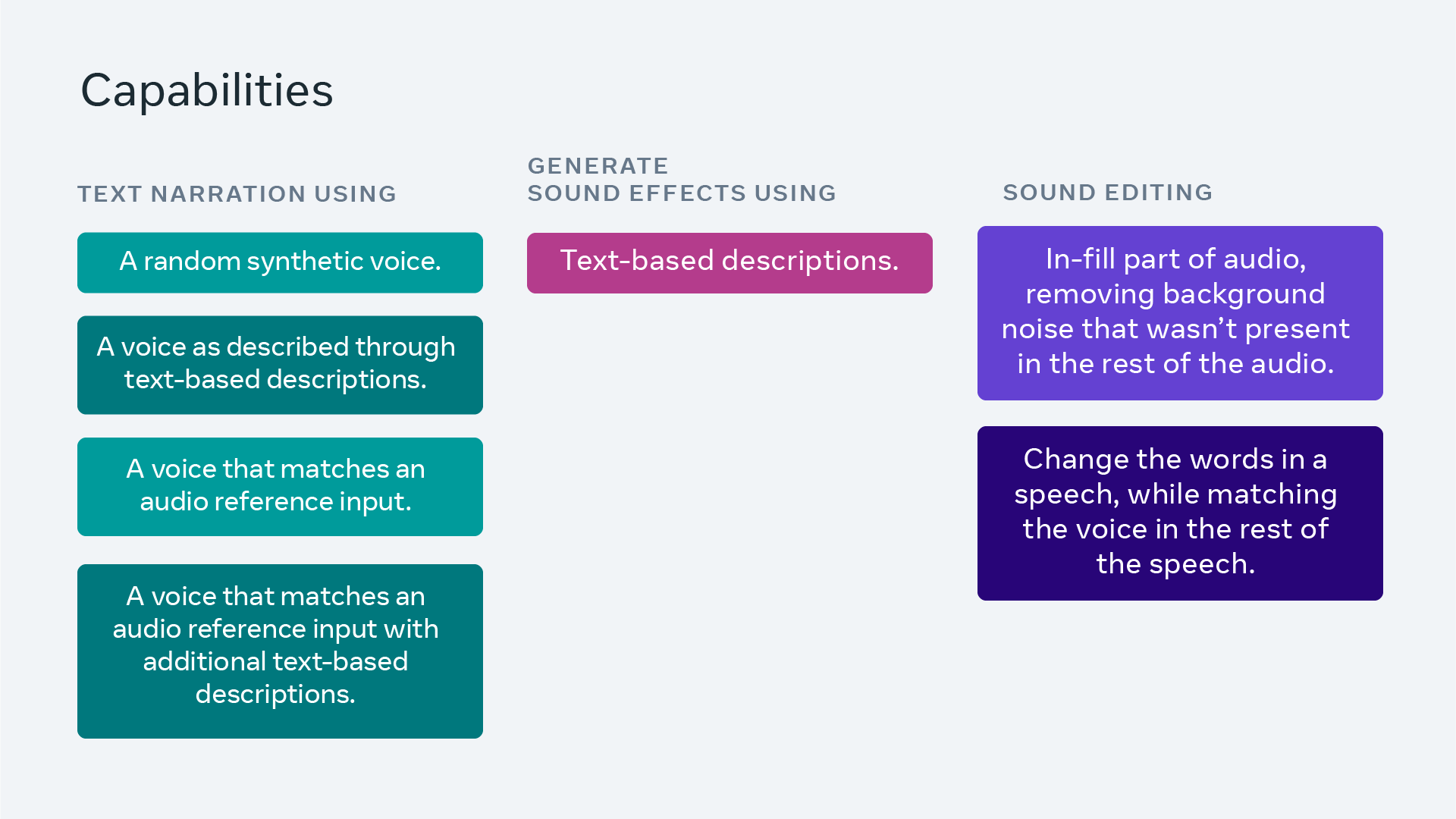
Audio Box의 주요 장점
- 음성과 텍스트 프롬포트를 결합해서 다양한 환경이나 감정으로 음성을 재스타일링 할 수 있습니다. 예를 들어 "대성당 안에서 슬프고 느리게 말하는 소리" 를 입력하면 상황에 맞는 오디오를 만들 수 있습니다.
- 또 다른 주요한 기능은 오디오 인피링(Generative Infilling)으로 오디오 세그먼트를 자르고 재생성하면서 원하는 오디오를 만들 수 있습니다. 예를 들어 "비 내리는 소리에 개 짖는 소리 추가" 같은 효과를 삽입할 수 있어요.
우려점
- Meta는 이 기술이 목소리 모방이나 오남용에 대한 우려를 방지하기 위해서 Audiobox에 자동 오디오 워터마킹 기능을 도입하여, AI가 생성한 오디오의 출처를 정확하게 추적할 수 있도록 했어요.
- 이 워터마킹 방법은 인간 귀에는 눈에 띄지 않지만, AI 생성 오디오를 감지할 수 있는 모델을 사용하여 프레임 수준까지 탐지할 수 있답니다.
장기적으로는 모든 사용자가 자신의 필요에 맞는 오디오를 더 쉽고 효율적으로 만들 수 있게 될 것 같아요. Audiobox가 가져올 오디오 생성의 미래가 궁금합니다.
링크 : AudioBox
Audiobox: Generating audio from voice and natural language prompts
Similarly, to generate a voice, a user might input, “A young woman speaks with a high pitch and fast pace.” Describe-and-generate speech: Users can provide a short description of the desired voice, along with the transcript to be narrated, and ask the
ai.meta.com
'AI 소식' 카테고리의 다른 글
| 춤추는 모나리자를 만들 수 있다고? - MagicAnimate (46) | 2023.12.10 |
|---|---|
| 어쩌면 챗GPT를 무너뜨릴 구글의 AI - Gemini (3) | 2023.12.07 |
| AI로 할 수 있는 Upscaling의 신세계 - Magnific AI (3) | 2023.12.06 |
| 챗 GPT보다 똑똑한 의료 인공지능 - Towards Accurate Differential Diagnosis with Large Language Models (1) | 2023.12.04 |
| Google이 가져올 새로운 혁신 - Google Deepmind 의 GNoME (7) | 2023.12.03 |